How does a Cloud SQL database scale?
One of the most challenging decisions when designing a new system is choosing your data storage solution. There are many aspects to consider, performance and scalability being usually the fundamental ones. I have been through this exercise many times and I always felt there’s not enough good documentation on what performance to expect from Cloud SQL11. I’ll be using PostgreSQL flavour in this post, but most of the material can be directly applied to the other variants as well. database and how does it scale.
Performance aspects
Let’s start by going over the main configuration choices that will directly influence the performance of your Cloud SQL instance.
CPU & memory
No surprise here - more CPU and memory will give you better performance. You can choose arbitrary number of CPU cores, starting from 1 shared core 22. Shared-core instances are not recommended for production workloads and not covered by SLA and 0.6 GiB of memory up to 64 dedicated vCPUs and 416 GiB of memory.
It’s important to realise that the number of vCPUs will also directly influences the network performance of your instance. Network egress bandwidth starts at 1 Gbps for shared core instances and goes up to 32 Gbps33. Skylake or newer CPU platform is required, otherwise, you’re capped at 16 Gbps. for instances with 16+ cores. Don’t forget that network bandwidth is shared by both application and storage traffic, and if saturated, both will be competing with each other.
Note: While instance type is another important aspect influencing the performance, at the moment Cloud SQL - PostgreSQL only supports the first generation of general-purpose machine types - N1.
Disk type and size
Performance of SSD persistent disks44. SSD is the default type for Cloud SQL scales linearly with its size, until it reaches the limit imposed by your instance egress. Starting at 300/300 r/w IOPS and 4.8/4.8 MB/s throughput for a 10 GB volume, going up to 100k/30k r/w IOPS and 1200/800 MB/s throughput for a 4 TB one55. SSD persistent disks can achieve maximum throughput for both reads and writes simultaneously, but not maximum IOPS for both. Standard persistent disks share the same resources for both.. For Standard persistent disks the performance starts at 24/48 r/w IOPS for a 32 GB volume and tops at 7.5k/15k IOPS and 1200/400 MB/s throughput for 10 TB and larger volumes.
Note on HA and downtime
Somewhat surprising might be that you can’t expect zero downtime of your Cloud SQL instance, not even in HA configuration66. Cloud SQL HA configuration is using synchronous replication of writes to underlying storage across two zones - primary and standby. As such, HA configuration will not improve your read performance in any way, because the standby instance cannot be used for queries.. HA provides data redundancy and shortens downtime in case of instance or zone failure, but it will still suffer from downtime on regular updates (these can happen up to once a week, although typically less than once a month). Downtime will also be required for scaling the instance.
There are strategies on how to mitigate this, but that’s beyond the scope of this article. Sufficient to say that Cloud SQL does not offer any way how to do that out of the box.
Topology
In order to get the best performance, you will want to provision private SQL instance and access it over the private IP address (with the public one, traffic would go over the internet and everything would be way slower). Technically the instance is provisioned in separate VPC and then VPC peering is established between your VPC and the one managed by Google.
PostgreSQL tuning
There are many options to further customize your Cloud SQL instance, apart from just choosing the version77. PostgreSQL versions 11 (default), 10, and 9.6 are currently available. Both database flags and installed extensions will affect the performance as well, but for the purpose of this test all settings were kept at their defaults.
Testing setup
The tests were executed from a client instance, sitting in the same VPC, same
region and zone, in order to minimise network impact. In this particular case,
all the instances were provisioned in London (europe-west2-a).
The client instance was n2-highcpu-16 - notice a high number of CPUs to get
high network performance. Client OS was default debian-cloud/debian-9 image,
without any further performance tuning.
Tested was PostgreSQL version 11, in HA configuration. Disk size of 4 TB was chosen to avoid any throttling of the storage. The instance was provisioned as private and accessed using the private IP.
pgbench setup
I’ve used pgbench, which is a simple benchmark tool bundled with PostgreSQL. By default, it runs scenario that is loosely based on TPC-B, and executes several SELECT, UPDATE and INSERT operations per transaction88. You can find more details about the executed queries and pgbench in general at https://www.postgresql.org/docs/11/pgbench.html..
The test would always run for five minutes, five iterations per tested configuration
in total, with one initial “pre-warm” run which is not reflected in the results.
Number of worker threads (-j) within pgbench was set to 8, scale factor (-s)
to 100, the rest kept at their defaults. I’ve tried to experiments with some of
these further, but apart from the settings mentioned later didn’t find these to
have a significant impact on the results.
Tested configurations
In the first, place I was interested in how the database performance scales with
the instance size. Tests were executed for instances starting with 1 vCPU up to
instances with 64 vCPUs and memory amount equal to number_of_cpus x 4 in GB
(basically this follows the standard instance sizing).
Let’s also look at how the number of parallel clients accessing the database affects performance - common scenario with multiple instances of the backend service(s). And finally, how much slower will everything be without connection pooling and with SSL on.
Code
The whole setup can be found as a code (Terraform mostly) in the stepanstipl/gcp-cloudsql-bench repository with additional details on how to reproduce the whole setup and execute the tests.
Results
General Performance and Latency
Fig. 1: Cloud SQL Performance
Fig. 1 shows that performance scales in a linear fashion up to 8-16 CPUs and flattens out afterwards. This was pretty much expected, and it’s interesting to see how exactly the curve looks like. What surprised me a bit was that the average latency was significantly worse for smaller instance sizes. Starting at 140 ms for 2 vCPU instances and only falling below 20 ms for instances with 16 and more vCPUs.
So what is actually limiting the performance? Fig. 2 shows that smaller instances were maxing out on the CPU, but larger ones were nowhere near the CPU, nor previously described network and disk limits. This brings up questions on what are we actually testing with pgbench and how meaningful this metric is? I won’t dig deeper in this direction99. I believe that while it might not help you to exactly pinpoint the bottlenecks of your database, it simulates typical real-world scenario fairly well. Great post on the topic by Frank Pachot., the answer is that in our scenario the machine spends a lot of time on context switching.
Fig. 2: Cpu and Network utilization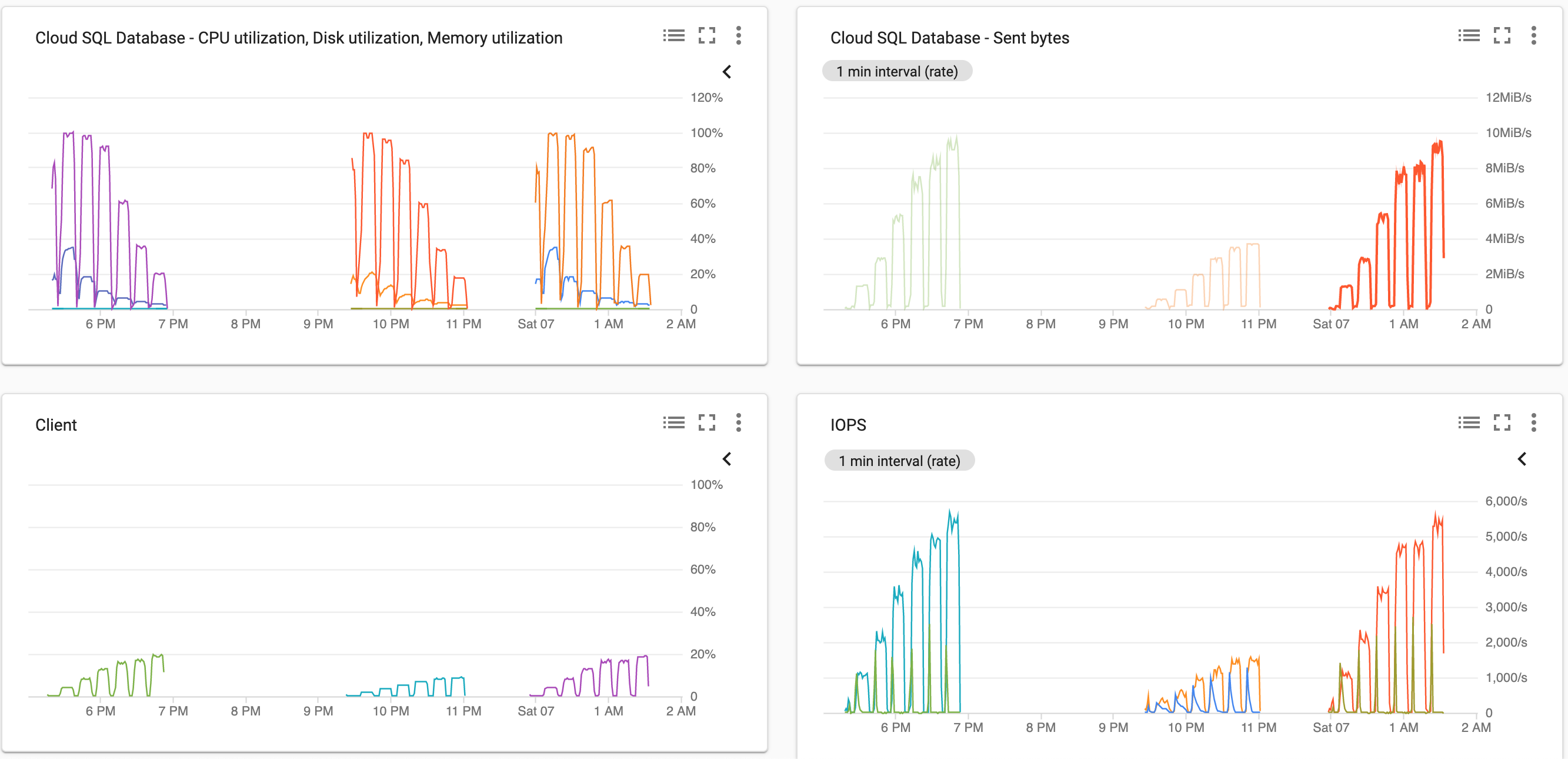
Concurrent Clients
Fig. 3: Performance - Concurrent Clients x TPS
Number of parallel connections did not have too significant effect, as long as
you stay within a reasonable range for the given instance size and TPS. We can
observe that 100 for smaller, and 200 concurrent clients for instances above 10 vCPUs
seemed to perform the best. Small instances do not support higher number of
connections by default (this can be changed by adjusting the max_connections
option) and suffer from higher performance hit for higher numbers of concurrent connections.
Fig. 4: Performance - Concurrent Clients x Latency Higher number of concurrent clients causes higher latency - fig. 4. Again, smaller
instances suffer more.
Higher number of concurrent clients causes higher latency - fig. 4. Again, smaller
instances suffer more.
Connection Pooling
Fig. 5: Performance - No Connection Pooling
Unsurprisingly, disabled connection pooling, when the client has to establish new connection for each request instead of reusing existing one, has significant impact both on TPS throughput and latency. And as obvious as this might seem, I wanted to demonstrate how huge the difference is, as I’ve repeatedly seen this issue on production systems. Enabling connection reuse is often one of the cheapest ways to improve your application performance.
SSL
Fig. 6: Performance - SSL
All the tests so far were performed without using SSL1010. Surprisingly
while sslmode should default to
prefer, and therefore one
would expect pgbench to use SSL by default, it doesn’t. I had to enforce SSL by
appending sslmode=require to the connection string., and
enabling it has expected negative performance effect on both TPS and latency -
fig. 6.
Data Stats
Fig. 7: Performance - stats
At last, let’s get some idea about consistency of the measured data. The last graph, fig. 7, shows the standard deviation for each series of runs. Each data point representing one series of 5 runs for the given instance size and number of concurrent clients. The results seem reasonably consistent, higher variation in performance can be observed for instances with high number of vCPUs (32, 64), while higher variation in latency can be observed for the smallest instance sizes.
Summary
Cloud SQL is a great hands-off way to run a very popular, well-performing and feature-rich database. Provision your instances with enough vCPUs and large enough disk size to get sufficient network bandwidth and disk IOPS. Also make sure that your connecting using the private IP, your application uses connection pooling, and expect occasional short downtime, even when using the HA mode. Keep in mind that PostgreSQL is not designed as a distributed system and if you require true zero downtime or near-linear scalability above what a single machine can handle, there might be more suitable database choices.
Hopefully, this will be useful as a rough guide on what to expect when considering Cloud SQL as the database option for your workload. Keep in mind it is a very generic test and I would always encourage you to test yourself, using more specific benchmark that better reflects the behaviour of your application.
Let me know about your experience with Cloud SQL or if you have any additional suggestions or questions. You can also find me at @stepanstipl. Happy life in the ☁☁☁!
References
- Code: https://github.com/stepanstipl/gcp-cloudsql-bench
- GCP - Cloud SQL for PostgreSQL documentation: https://cloud.google.com/sql/docs/postgres
- GCP - Block storage performance: https://cloud.google.com/compute/docs/disks/performance
- GCP - N1 standard machine types - Network egress bandwidth: https://cloud.google.com/compute/docs/machine-types#n1_standard_machine_types
- PostgreSQL - pgbench: https://www.postgresql.org/docs/10/pgbench.html
- Do you know what you are measuring with pgbench? by Franck Pachot: https://medium.com/@FranckPachot/do-you-know-what-you-are-measuring-with-pgbench-d8692a33e3d6